Yang S, Li G, Yu Y. Cross-Modal Relationship Inference for Grounding Referring Expressions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 4145-4154.
1. Overview
1.1. Motivation
- existing work can not extract multi-order relationships
In this paper, it proposes
1) Cross-Modal Relationship Extractor (CMRE)
2) Gated Graph Convolutional Network (GGCN)
Graph Construct:
1) spatial relation graph $G^s=(V, E, X^s)$
2) language-guided visual relation graph $G^v=(V, E, X, P^v, P^e)$
3) multimodal (language, visual and spatial information) relation graph $G^m=(V, E, X^m, P^v, P^e)$
4) propagate with gated operation
1.2. Dataset
- RefCOCO
- RefCOCO+
- RefCOCOg

2. Cross-Modal Relationship Inference Network
2.1. CMRE
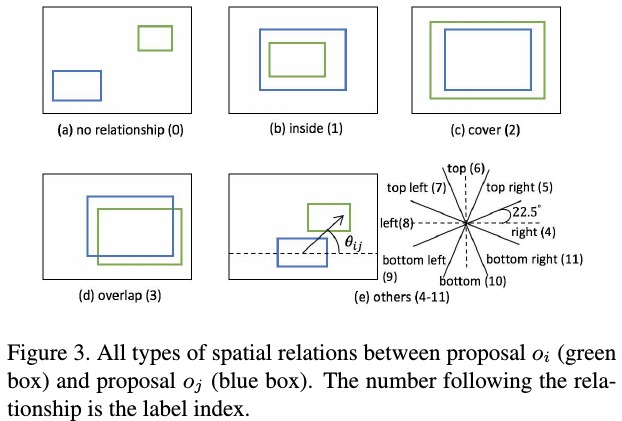
2.1.1. Spatial Relation Graph
$G^s$.
1) Node. visual feature $v_i$ from pretrained CNN model
2) Edge. $e_{ij}$ from 1 to $N_e=11$
2.1.2. Language Context
1) softly classify the words in the expression into four types (entity words, relation, absolute location and unnecessary words)
2) $m_t = [m_t^{(0)}, m_t^{(1)}, m_t^{(2)}, m_t^{(3)}]$



2.1.3. Language-Guided Visual Relation Graph
highlight the vertices and edges of $G^s$, that have connections with the referring expression, to generate $G^v$.
1) gate for $v_i$ according to the expression
2) gate $p_j^e$ for edge with type $j=1, 2, …, N^e$

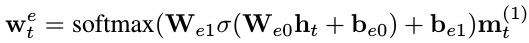

$P^v=p_i^v, i=1,…,K$
$P^e=p_j^e, j=1,…,N_e$
2.2. Multimodal Context Modeling
generate $G^m$.
2.2.1. Language-Vision Feature
$x_i^m = [x_i^s, c_i]$
2.2.2. Semantic Context Modeling
GGCN.

1) →,←. encoded feature for out- and in- relationships respectively
2) finally get semantic contexts $X^c=x_i^c, i=1,…,K$
3) for each $v_i$, $x_i=[W_p p_i, x_i^c]$, encode spatial feature $p_i$.
2.3. Loss Function

